





基于 so-vits-svc4.0(V1)的一个分支,支持实时推理和图形化推理界面。
- 实时语音转换 (增强版本 v1.1.0)
- 使用 CREPE 进行更准确的音高推测
- 图形化界面
- 统一命令行界面(无需运行 Python 脚本)
- 只需使用
pip安装即可使用 - 自动下载预训练模型和 HuBERT 模型
- 使用 black、isort、autoflake 等完全格式化的代码
- 还有一些细微差别
通过 pip 安装 (或者通过包管理器使用 pip 安装):
python -m pip install -U pip setuptools wheel
pip install -U torch torchaudio --index-url https://download.pytorch.org/whl/cu117
pip install -U so-vits-svc-fork- 如果没有可用 GPU, 不需要执行
pip install -U torch torchaudio --index-url https://download.pytorch.org/whl/cu117. - 如果在 Linux 下使用 AMD GPU, 请使用此命令
--index-url https://download.pytorch.org/whl/rocm5.4.2替换掉--index-url https://download.pytorch.org/whl/cu117. Windows 下不支持 AMD GPUs (#120). - 如果
fairseq报错:- 如果提示
Microsoft C++ Build Tools没有安装. 安装即可. - 如果提示缺少 dll 文件, 重新安装
Microsoft Visual C++ 2022和Windows SDK可能有用
- 如果提示
请经常更新以获取最新功能和修复错误:
pip install -U so-vits-svc-fork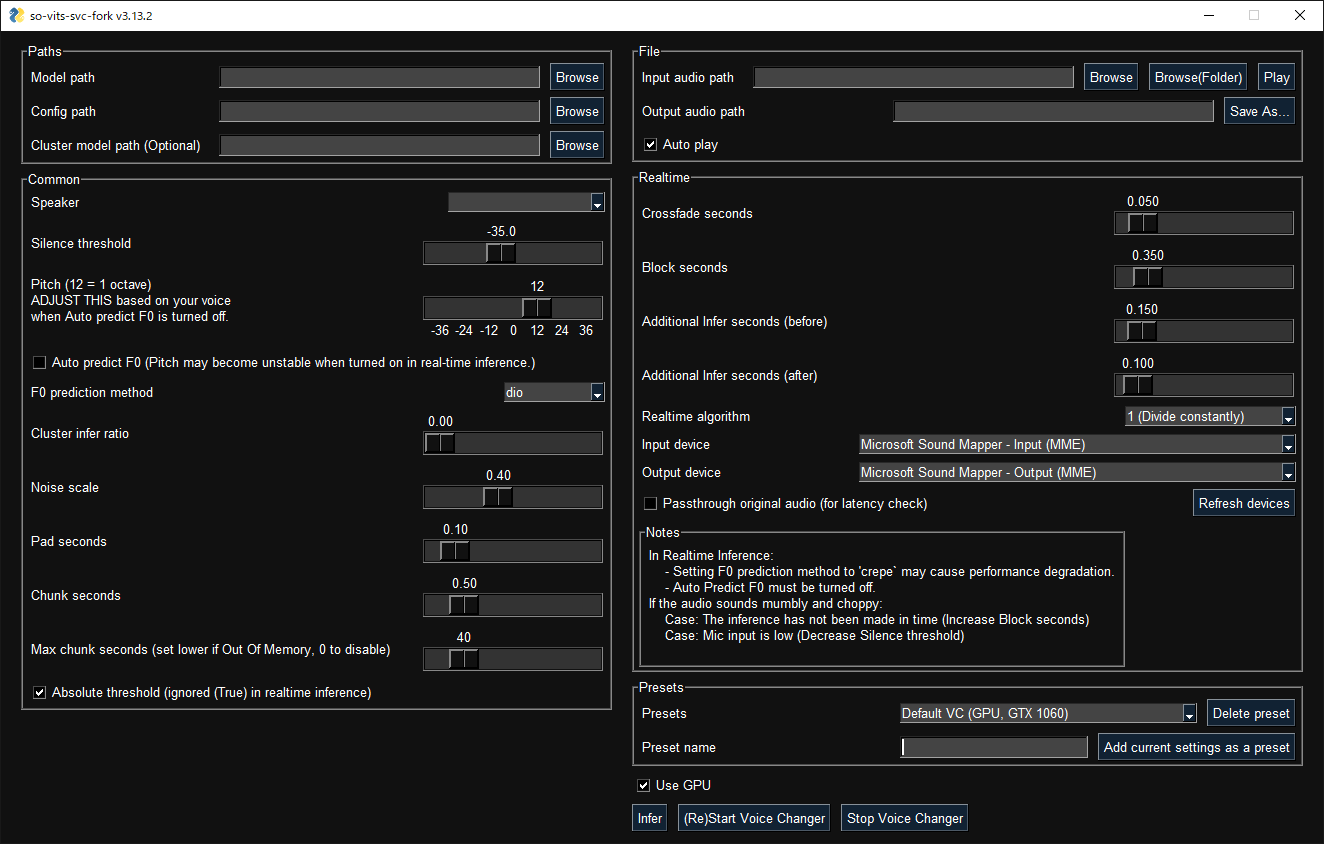
请使用以下命令运行图形化界面:
svcg- 实时转换 (输入源为麦克风)
svc vc --model-path <model-path>- 从文件转换
svc --model-path <model-path> source.wav预训练模型 可以在 HuggingFace 获得。
- 如果使用 WSL, 请注意 WSL 需要额外设置来处理音频,如果 GUI 找不到音频设备将不能正常工作。
- 在实时语音转换中, 如果输入源有杂音, HuBERT 模型依然会把杂音进行推理.可以考虑使用实时噪音减弱程序比如 RTX Voice 来解决.
- 如果数据集有 BGM,请用例如Ultimate Vocal Remover等软件去除 BGM.
推荐使用
3_HP-Vocal-UVR.pth或者UVR-MDX-NET Main. 1 - 如果数据集是包含多个歌手的长音频文件, 使用
svc pre-sd将数据集拆分为多个文件 (使用pyannote.audio) 。为了提高准确率,可能需要手动进行分类。如果歌手的声线多样,请把 --min-speakers 设置为大于实际说话者数量. 如果出现依赖未安装, 请通过pip install pyannote-audio来安装pyannote.audio。 - 如果数据集是包含单个歌手的长音频文件, 使用
svc pre-split将数据集拆分为多个文件 (使用librosa).
将数据集处理成 dataset_raw/{speaker_id}/**/{wav_file}.{any_format} 的格式(可以使用子文件夹和非 ASCII 文件名)然后运行:
svc pre-resample
svc pre-config
svc pre-hubert
svc train -t- 数据集的每个文件应该小于 10s,不然显存会爆。
- 如果想要 f0 的推理方式为 CREPE, 用
svc pre-hubert -fm crepe替换svc pre-hubert. 由于性能原因,可能需要减少--n-jobs。 - 建议在执行
train命令之前更改config.json中的 batch_size 以匹配显存容量。 默认值针对 Tesla T4(16GB 显存)进行了优化,但没有那么多显存也可以进行训练。 - 在原始仓库中,会自动移除静音和进行音量平衡,且这个操作并不是必须要处理的。
更多命令, 运行 svc -h 或者 svc <subcommand> -h
> svc -h
用法: svc [OPTIONS] COMMAND [ARGS]...
so-vits-svc 允许任何文件夹结构用于训练数据
但是, 建议使用以下文件夹结构
训练: dataset_raw/{speaker_name}/**/{wav_name}.{any_format}
推理: configs/44k/config.json, logs/44k/G_XXXX.pth
如果遵循文件夹结构,则无需指定模型路径,配置路径等,将自动加载最新模型
若要要训练模型, 运行 pre-resample, pre-config, pre-hubert, train.
若要要推理模型, 运行 infer.
可选:
-h, --help 显示信息并退出
命令:
clean 清理文件,仅在使用默认文件结构时有用
infer 推理
onnx 导出模型到onnx
pre-config 预处理第 2 部分: config
pre-hubert 预处理第 3 部分: 如果没有找到 HuBERT 模型,则会...
pre-resample 预处理第 1 部分: resample
pre-sd Speech diarization 使用 pyannote.audio
pre-split 将音频文件拆分为多个文件
train 训练模型 如果 D_0.pth 或 G_0.pth 没有找到,自动从集线器下载.
train-cluster 训练 k-means 聚类模型
vc 麦克风实时推理Thanks goes to these wonderful people (emoji key):
 34j 💻 🤔 📖 💡 🚇 🚧 👀 |
 GarrettConway 💻 🐛 📖 |
 BlueAmulet 🤔 💬 💻 |
 ThrowawayAccount01 🐛 |
 緋 📖 🐛 |
 Lordmau5 🐛 💻 |
 DL909 🐛 |
 Satisfy256 🐛 |
 Pierluigi Zagaria 📓 |
 ruckusmattster 🐛 |
 Desuka-art 🐛 |
 heyfixit 📖 |
 Nerdy Rodent 📹 |
This project follows the all-contributors specification. Contributions of any kind welcome!