Hello, I am kevin,
Here in this project, i will cluster data points based on their respective credit card information.
First, we perform data cleaning first to remove the columns that is empty or without values.
After that, we do data manipulation which include standardization of the data values.
Then, we reduce the dimensionality of the data using Principal Component Analysis(PCA)
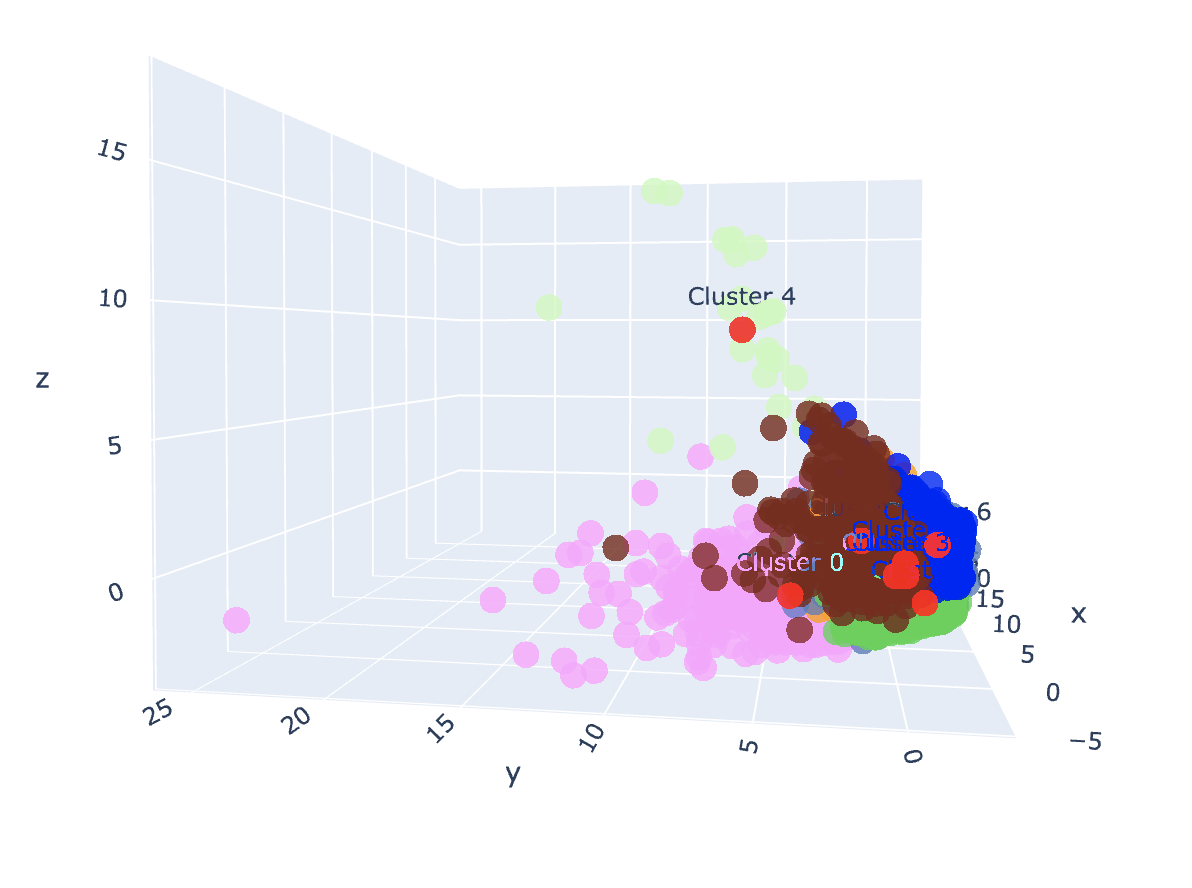
Finally, using K-Means Clustering Algorithm, unsupervised machine learning, I have clustered the data into number of clusters as well as provide its visualisation in 3D using interactive plot provided by plotly.
Therefore, with the help visualising the data, the company may able to group the customers based on their respective similarity (Group segregation)
Image 1

Image 2

Image 3 (only centroids are shown)

Image 4