
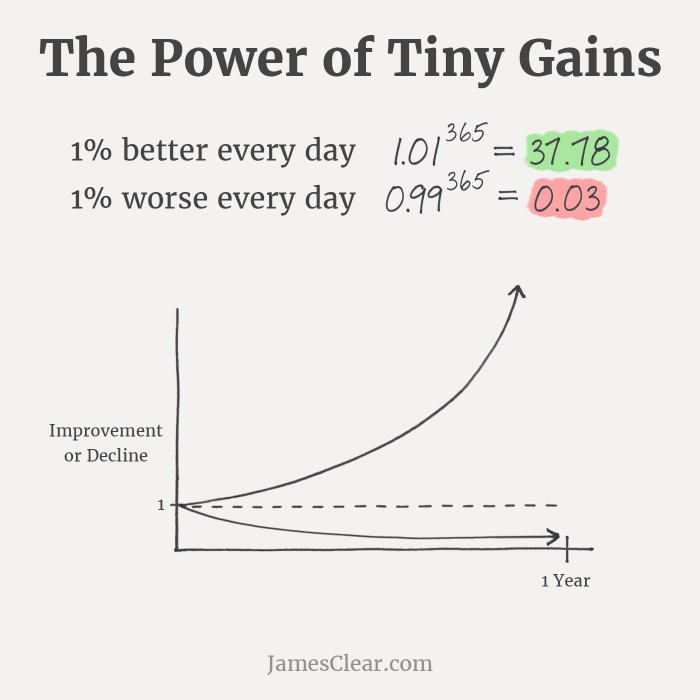
Becoming 1% better at everything I want. Starting from Aug 2nd, I will note my progress here everyday.
- Building and better understanding vision-language models: insights and future directions
- Phi3-vision
- InternLM
- Building makemore Part 3: Activations & Gradients, BatchNorm -
41:06/1:55:57 - Sampling - Temperature, Top-k & Top-P
- LLMs in depth
- Llama-2: Changes done to GPT2 to get Llama 2 and 3
- clip, siglip and paligemma by [umar-jamil]
- Flash attention and all softmax derivates
-
3:17:00/7:00:00Umar Jamil - Understanding Flash Attention and Coding the Kernel with Triton
- Deepseek R1 blog: Overview on R1 training with code and outputs
- Layer Skip: Early exit inference and self-speculative decoding
- Speculative decoding
- .txt about how structured generation works under hood
- Universal Assisted Generation
- Dynamic speculative decoding
- LLMs go brrr by first principles
- LLM inference talk by Nvidia
- Transformers Inference Optimization Toolset
-
31/38- how to make llms go fast by [vgel] - Understanding k-quants
- 1.5 bit quantization
- Turbo LoRa
- Flex Attention
- ML Engineering Book
- Talk on practical LLM merging
- What are OpenAI functions
- LangChain docs on Memory state for LLMs & ChatLMs
- The FASTEST way to build CHAT UI for LLAMA-v2
- Continuous blog on learning about building a custom LLM "SuperHot"
- All info about RoPE
- Learning with code: Rotary Positional Embeddings (RoPE)
- RoPE scaling
- Mastering LLMs course
- LLM.int8() and Emergent Features
- CPU land: Quick bytes on multiprocessing, forking, paging and so on
- Dockers -
1:50:00/5:16:45 - Docker For Data Scientists
- Understanding CoRoutines- async & await. FastAPI docs
- Binder: Repo2Docker
- Basic Intro to DVC, CML and MLFlow
- CML with Gitlab
- Youtube: Jekyll - Static Site Generator Playlist
- Useful tools for ML Engineer
- CS329S Machine Learning Systems Design
- The Missing Semester
- CI/CD pipeline
- Kubernetes
- Kubeflow
- Blog: How to improve software engineering skills as a researcher
- Learn PostgreSQL
- Towards a Fully Automated Active Learning Pipeline
- End-End & open source MLOps toolkit
- Comparison of experiment tracking tools
- D Ways to speed-up the deployment process?
- Towards MLOps: Technical capabilities of a Machine Learning platform
- PyTorch Performance Tuning Guide - Szymon Migacz, NVIDIA
- Airflow DAG: Coding your first DAG for Beginners
- Study material to become an ML engineer
- Managing the Model Artifacts?
- Getting started with Torchserve: Learn Torchserve with examples + Introducing the management dashboard
- Launching DAGsHub integration with MLflow
- How to deploy PyTorch Lightning models to production
- ML Deployment Decision Tree
- What is ML Ops? Best Practices for DevOps for ML (Cloud Next '18)
- MLOps - GitHub Repo - List of Articles/Blogs
- ML Ops - DVCorg
- MLOps Tutorial #1: Intro to Continuous Integration for ML
- MLOps Tutorial #2: When data is too big for Git
- MLOps Tutorial #3: Track ML models with Git & GitHub Actions
- MLOps Tutorial #4: GitHub Actions with your own GPUs
- DVC Explained in Five Minutes
- MLOps Tutorial #5: Automated Testing for Machine Learning
- MLOps Tutorial #6: Behavioral tests for models with GitHub Actions
- Elle O'Brien - Adapting continuous integration and continuous delivery for ML
- Blogs on ML-Production: Proper release and monitoring of machine learning systems in production.
- Blogs on Unit testing for ML
- Blogs on Continuous Integration / Continuous Deployment (CI/CD)
-
Blog:Continuous Machine Learning (CML) is CI/CD for ML - DVC Implementation: Completed setting up a project and running a pipeline
- MLOps: Accelerating Data Science with DevOps - Microsoft
- MLflow: An Open Platform to Simplify the Machine Learning Lifecycle
- Full Stack Deep Learning Course
- 1. Setting up Machine Learning Projects
- 2. Infrastructure and Tooling
- 2.1 Overview : Components of a Machine Learning system?
- 2.2 Software Engineering: Good SEngg practices for ML developers?
- 2.3 Computing and GPUs (3) - Infrastructure & Tooling
- 2.4 Resource Management (4) - Infrastructure & Tooling
- 2.5 Frameworks & Distributed Training (5) - Infrastructure & Tooling
- 2.6 Experiment Management (6)
- 2.7 Hyperparameter Tuning (7)
- 2.8 All-in-one Solutions (8)
- 3. Data Management
- 4. Machine Learning Teams
- 5. Training and Debugging
- 6. Testing and Deployment
- 6. Testing and Deployment
- 7. Research Areas
- Full Stack Deep Learning Course - 2021
- Organize Your Machine Learning Pipelines with Artifacts
- How to Deploy Machine Learning Models
- Snorkel: Dark Data and Machine Learning - Christopher Ré
- Snorkel: Programming Training Data with Paroma Varma of Stanford University (2019)
- Snorkel: Tweet asking Custom Snorkel Annotation Functions
- FAQ #1: Tips & tricks for NLP, annotation & training with Prodigy and spaCy
- TRAINING A NEW ENTITY TYPE with Prodigy – annotation powered by active learning
- Training a NAMED ENTITY RECOGNITION MODEL with Prodigy and Transfer Learning
- 5 NLP Libraries Everyone Should Know | by Pawan Jain | Jul, 2020 | Towards Data Science: spaCy, NLTK, Transformers, Gensim, and Stanza
- fine-tuned (distil)GPT-2 on "Amazon fine food reviews dataset".
- TextAttack
- Checklist
- PET: Cloze Questions
- Question Generation using Google T5 @Hugginface, Text2Text , Sense2Vec and FastApi.
- The Hugging face Transformers master branch now includes a built-in pipeline for zero-shot text classification, to be included in the next release.
- Language Interpretability Tool (LIT)
- How to Fine-Tune BERT Transformer with spaCy 3
- Tools & Flow for reproducible deep learning
- NLP guide from AllenNLP
- Is there any approach to normalize words like helllllloooooo to hello?
- BioBERT for Medical Domain
- Codequestion: Ask coding questions directly from the terminal
- NLP models Template generation - HuggingFace
- DiffBot - Observations on various tasks
- Argos-Translate -> Open source offline translation app written in Python. Uses OpenNMT for translations.
- Extract transliteration pairs from a parallel corpus using Moses
- Text-to-SQL Generation for Question Answering on Electronic Medical Records
- HuggingFace NeuralCoref blog on how they are doing Coreference resolution
- How to train a neural coreference model— Neuralcoref 2
- TorchMetrics V0.2, a collection of #PyTorch metric implementations.
- Talk: Camelot -> Extracting Tables from PDFs
- Git repo: Making Language Models like BERT, ALBERTA etc good at Sentence Representations
- Faker: Generates fake data for you like fake names, address etc
- Label-Studio: Setup and map with a ML model
- Gradio: Quickly create customizable UI components around your TensorFlow or PyTorch models, or even arbitrary Python functions.
- UBIAI: Easy-to-Use Text Annotation for NLP Applications
- Production scale, Kubernetes-native vision AI platform, with fully integrated components for model building, automated labeling, data processing and model training pipelines.
- CascadeTabNet - Cascade mask R-CNN HRNet to detect Tables
- Text Recognition with CRNN-CTC Network
- VS Code (codeserver) on Google Colab / Kaggle / Anywhere
- OpenRefine Lib for cleaning, managing data
- RasaLitHQ: bulk labelling with a ui from a jupyter notebook
-
Are categorical variables getting lost in your random forests
-
- 1. Introduction and Word Vectors
- 2. Word Vectors and Word Senses
- 3. Neural Networks
- 4. Backpropagation
- 5. Dependency Parsing
- 6. Language Models and RNNs
- 7. Vanishing Gradients, Fancy RNNs
- 8. Translation, Seq2Seq, Attention
- 9. Practical Tips for Projects
- 10. Question Answering
- 11. Convolutional Networks for NLP
-
57:00/1:1512. Subword Models - 13. Contextual Word Embeddings
- 14. Transformers and Self-Attention
- 15. Natural Language Generation
- 16. Coreference Resolution
- 17. Multitask Learning
- 18. Constituency Parsing, TreeRNNs
- 19. Bias in AI
- 20. Future of NLP + Deep Learning
-
5/9- Entity Projection via Machine-Translation for Cross-Lingual NER - Zero-Resource Cross-Lingual Named Entity Recognition
-
8/8- Neural Cross-Lingual Named Entity Recognition with Minimal Resources -
4/9- Word Alignment by Fine-tuning Embeddings on Parallel Corpora - UniTrans : Unifying Model Transfer and Data Transfer for Cross-Lingual Named Entity Recognition with Unlabeled Data
- Baseline setup of BERT variants-NER integrated with wandb
-
- Entailment as Few-Shot Learner
- NLP Checklist Paper
-
6/9- Benchmarking Zero-shot Text Classification: Datasets, Evaluation and Entailment Approach - Let Me Choose: From Verbal Context to Font Selection
-
6/9- Cross-lingual Language Model Pretraining -
4/8- A Multilingual View of Unsupervised Machine Translation - The First Cross-Script Code-Mixed Question Answering Corpus
-
9/17- Multilingual Denoising Pre-training for Neural Machine Translation - Transforming machine translation: a deep learning system reaches news translation quality comparable to human professionals
- OverView of Explicit Cross-lingual Pre-training for Unsupervised Machine Translation
-
6/8- A unified framework for evaluating the risk of re-identification of text de-identification tools -
3/9- Movement Pruning: Adaptive Sparsity by Fine-Tuning - On the Cross-lingual Transferability of Monolingual Representations.
- Prefix-tuning: Train small, continuous vectors to act as 'prompts' for different downstream tasks in GPT-2 and BART.
- Warning sign If you are using a pretrained transformer, data augmentation doesn’t help : How Effective is Task-Agnostic Data Augmentation for Pretrained Transformers?
- Self-training Improves Pre-training for Natural Language Understanding
- Investigating representations of verb bias in neural language models
- Using Multilingual Entity linking, we can automatically evaluate Machine Translation. KoBE: Knowledge-Based Machine Translation Evaluation
- Multilevel Text Alignment with Cross-Document Attention
- The elephant in the interpretability room: Why use attention as explanation when we have saliency methods?
- MAD-X : An Adapter-based Framework forMulti-task Cross-lingual Transfer
- It's Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners
- Utility is in the Eye of the User: A Critique of NLP Leaderboards
- FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence
- ‘Less Than One’-Shot Learning: Learning N Classes From M<N Samples
- Grounded Compositional Outputs for Adaptive Language Modeling
- Plug and Play Autoencoders for Conditional Text Generation
- Not Low-Resource Anymore: Aligner Ensembling, Batch Filtering, and New Datasets for Bengali-English Machine Translation
- Participatory Research for Low-resourced Machine Translation: A Case Study in African Languages
- Human Attention Maps for Text Classification: Do Humans and Neural Networks Focus on the Same Words?
- iNLTK: Natural Language Toolkit for Indic Languages
- Knowledge-Aware Language Model Pretraining
- Integrating Semantic Knowledge to Tackle Zero-shot Text Classification
- Vokenization: a visually-supervised language model attempt
- Self-training Improves Pretraining for Natural Language Understanding
- Continual Learning and Active Learning
- Design Challenges for Low-resource Cross-lingual Entity Linking
- Pre-train and Plug-in: Flexible Conditional Text Generation with Variational Auto-Encoders
- Contextualized Weak Supervision for Text Classification
- AllenNLP Interpret: A Framework for Explaining Predictions of NLP Models
- Pre-training via Paraphrasing
- A language model you can add symbolic facts to!
- Perturbation sensitivity analysis to detect unintended model biases
- Asking Crowdworkers to Write Entailment Examples: The Best of Bad Options
- Big Bird: Transformers for Longer Sequences
- The State and Fate of Linguistic Diversity and Inclusion in the NLP World
- A Call for More Rigor in Unsupervised Cross-lingual Learning
-
5/5- Publicly Available Clinical BERT Embeddings -
4/7- ClinicalBERT: Modeling Clinical Notes and Predicting Hospital Readmission - Deploying Lifelong Open-Domain Dialogue Learning
- The Woman Worked as a Babysitter: On Biases in Language Generation
- Annotated Paper on What should not be Contrastive in Contrastive learning
- Generative Language Modeling for Automated Theorem Proving
- Investigating Gender Bias in BERT
- The Return of Lexical Dependencies: Neural Lexicalized PCFGs
- Utility is in the Eye of the User: A Critique of NLP Leaderboards
- An Image Is Worth 16X16 Words: Transformers For Image Recognition At Scale
- Compositional Explanations of Neurons
- Leakage-Adjusted Simulatability: Can Models Generate Non-Trivial Explanations of Their Behavior in Natural Language? and its Tweet
- "You are grounded!": Latent Name Artifacts in Pre-trained Language Models
- Unsupervised Commonsense Question Answering with Self-Talk
- Understanding Self-supervised Learning with Dual Deep Networks
-
- Ilya GPT-2 Talk
- NLP Idiots
- Getting Started With Diffbot's Excel Add-In: Data Enrichment
- Getting Started With Diffbot's Excel Add-In: Lead Generation
- VLDB2020: The Diffbot Knowledge Graph
- Data Augmentation using PreTrained Models
- SpanBERT: Improving Pre-training by Representing and Predicting Spans | Research Paper Walkthrough
- Please Stop Doing "Explainable" ML - Cynthia Rudin
- Text Data Augmentation Made Simple By Leveraging NLP Cloud APIs - Claude Coulombe
- Well-Read Students Learn Better
- Easy Data Augmentation for Text Classification
- TextAttack: A Framework for Data Augmentation and Adversarial Training in NLP
- ACL 2019 tutorial on Unsupervised Cross-lingual Representation Learning
- Small Language Models Are Also Few-Shot Learners
- REALM: Retrieval-Augmented Language Model Pre-Training | NLP Journal Club
- Knowledge Graph made simple using NLP and Transfer Learning by Suyog Swami
- Building a Knowledge Graph Using Messy Real Estate Data | Cherre
- Linkedin's New Search Engine | DeText: A Deep Text Ranking Framework with BERT | Deep Ranking Model
- The Hardware Lottery (Paper Explained)
- The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks
- Training more effective learned optimizers, and using them to train themselves (Paper Explained)
-
- Neural Machine Translation Inside Out
- Basic Intro to Pruning
- Why You Should Do NLP Beyond English
- Simple Ways to Tackle Class Imbalance
- Custom NLP Approaches to Data Anonymization
- NLP Keeps Stealing From CV 👨🏻🎤 Why NLP engineers shouldn’t stop learning CV
- Introducing Label Studio, a swiss army knife of data labeling
- How to Skim Through Research Paper
- TaBERT: A new model for understanding queries over tabular data
- Adaptive Risk Minimization: Adapting to new test distribution in production
- How we sped up transformer inference 100x for 🤗 API customers
- Attention Is Not All You Need: Google & EPFL Study Reveals Huge Inductive Biases in Self-Attention Architectures
- Pruning BERT to accelerate inference
- Unsupervised NER using BERT
- Maximizing BERT model performance
- Comprehensive Language Model Fine Tuning, Part 1: 🤗 Datasets library - Normalizing
- MixUp Augmentation
- Paper -> Adjective ordering is universal across languages
- Should you deploy and use Semi-Supervised Learning in production? -> From Research to Production with Deep Semi-Supervised Learning
- On the Ability and Limitations of Transformers to Recognize Formal Languages
- WTF is a knowledge graph?
- Introduction to Knowledge Graphs and their Applications
- Challenges of Knowledge Graphs
- Building a knowledge graph in python from scratch
- Measuring dataset similarity using optimal transport
- The Best NLP Papers From ICLR 2020
- What is XLNet and why it outperforms BERT -> Basic knowledge of XLNet to understand the difference between XLNet and BERT intuitively
- Paper Dissected: “XLNet: Generalized Autoregressive Pretraining for Language Understanding” Explained
- Understand the Two-Stream Self-Attention in XLNet intuitively
- Is Hopfield Networks All You Need?
- Hopfield Networks is All You Need
- Challenges in going from POCs to Production-Ready ML system
- CodeMix: A Semi-supervised Approach to Generate the Code-mixed Text using Pre-trained Encoder and Transfer Learning
- iNLTK Feature: CodeMix for Indic Languages: About generating synthetic code-mix data
- Transformers-based Encoder-Decoder Models
- How to generate text: using different decoding methods for language generation with Transformers
- GLUCOSE: GeneraLized & COntextualized Story Explanations
- PyCon India 2020 Interesting Talks
- Under the Hood of Sequence Models
- How are spaCy models trained in the background?
- Tutorial: Training on larger batches with less memory in AllenNLP
- Knowledge Distillation
- Achieving Human Parity on Automatic Chinese to English News Translation
- Introducing UBIAI: Easy-to-Use Text Annotation for NLP Applications
- Developments in NLP from RNNs(1985) to Big Bird(2020).
- Hugging Face - 🤗Hugging Face Newsletter Issue #2
- Few-Shot Learning with fast.ai
- Zero-Shot Learning in Modern NLP
- Topic Modeling! Leveraging BERT, and TF-IDF to create easily interpretable topics - README of the repo
- Better Language Models and Their Implications
- Practical AI: Using NLP word embeddings to solve localization
- Introduction to Graph Neural Networks with GatedGCN
- Learning from imbalanced data
- Accelerate your Hyperparameter Optimization with PyTorch’s Ecosystem Tools
- Which Optimizer should I use for my Machine Learning Project?
- Tempering Expectations for GPT-3 and OpenAI’s API
- Effective testing for machine learning systems
- Deep Reinforcement Learning: Pong from Pixels
- Finding Cross-lingual Syntax
- Get rid of AI Saviorism
- An A.I. Training Tool Has Been Passing Its Bias to Algorithms for Almost Two Decades
- REALM: Integrating Retrieval into Language Representation Models
- Amazon’s open-source tools make embedding knowledge graphs much more efficient
- Amazon Web Services open-sources biological knowledge graph to fight COVID-19
- Intro to Adversarial Examples
- Adversarial Attack and Defense on Neural Networks in PyTorch
- FastAI - Course-2021
- Justin Johnson - Deep Learning for Computer Vision
- NYU Deep learning course - Interesting!!!!!
- Dive into Deep Learning
- ETH-Zurich Machine Learning
- Tweet mentioning a lot of cool apps
- Tweet mentioning a lot of traditional & popular courses
- Why Does Deep Learning Perform Deep Learning - MSR AI Seminar 08/11/2020
- NLP Course -> Interactive examples, intuitive explanations, lovely graphics.
- Slither Into Python
- Advanced Computer Vision
- Deep Learning for Computer Vision
- Amazing line-up of tutorials on self-supervised, semi-supervised & weakly-supervised learning.
- Intro to Causal Learning
- Curated list of tutorials, projects, libraries, videos, papers, books and anything related to the incredible PyTorch.
- MultiModal Machine Learning - C.M.U
- Multilingual Natural Language Processing
- CMU Multilingual NLP 2020 (1): Introduction -
1:17:28 - CMU Multilingual NLP 2020 (2): Typology - The Space of Language -
37:12 - CMU Multilingual NLP 2020 (3): Words, Parts of Speech, Morphology -
38:57 - CMU Multilingual NLP 2020 (4): Text Classification and Sequence Labeling
- CMU Multilingual NLP 2020 (5): Advanced Text Classification/Labeling -
49:39
- CMU Multilingual NLP 2020 (1): Introduction -
- CS 285: Deep Reinforcement Learning
- Essence of Linear Algebra
- Most extensive list of "From Scratch Machine Learning".
- Setting up SSL for website
- Fine-tuning with custom datasets & Tweet
- Easy GPT2 fine-tuning with @huggingface Transformers and @PyTorch using @GoogleColab
- Pruning Tutorial
- Decorators in Python
- How to generate text: using different decoding methods for language generation with Transformers
- Deep dive into simCLR with code-first approach ("A Simple Framework for Contrastive Learning of Visual Representations")
- Python Knowledge Graph: Understanding Semantic Relationships
- How to Get Started with Spark NLP in 2 Weeks
- Training RoBERTa from scratch - the missing guide
- Building Multi Page Web App Using Streamlit
- Interactive Analysis of Sentence Embeddings
- Custom classifier on top of BERT-like Language Model - guide
- Use @HelsinkiNLP's translation models transformers to do very cheap back translators for data augmentation
- Transformers' 1st-ever end-2-end multimodal demo - leveraging LXMERT, SOTA model for visual Q&A!
-
Video: nbdev tutorial - Fine-tune Transformers in PyTorch Using Hugging Face Transformers
- Comprehensive Language Model Fine Tuning, Part 1: 🤗 Datasets library - Normalizing
- Building an entity extraction model using BERT
-
Implementation: XLM-> HuggingFace Dataset & Model -
Implementation: XLM-> HuggingFace Model & Loss - Spacy exploration
- SparkNLP in 1 Hour
- Ensembling, Blending & Stacking
- Aakash Nain | Tensorflow 2.0 | TF Add-Ons | Good API Designs | CTDS.Show #90
- Connor Shorten | Creating AI Content, Videos, | Henry AI Labs, Research & GANs | CTDS.Show #76
- Episode #191: Live from the Manning Python Conference
- TwiMLAI- Causal Modeling in ML
- Text Classification Algorithms: A Survey
- A Survey of Evaluation Metrics Used for NLG Systems
- 100 Must-Read NLP Papers
- A Survey of Surveys (NLP & ML)
- Efficient Transformers: A Survey
- Towards MLOps: Technical capabilities of a Machine Learning platform
- On Exploting LMs. Refer nlp-helper tool as well
- Collate all - t5, marge, pegasus, electra etc.
- Explaining PDF backend
- On label-studio usage and mapping with ML: Fast in a day or two
- Optimizing code & reducing runtime from 2+ hours to 8 mins
- On DVC
-
3/365Shorts - HuggingFace GitLFS, Papermill, GPU dynamic select - Everything everywhere at once: Memory & State
-
- Let's Talk money -
62% - The Psychology of Money
- Recession Proofing My Tech Career Or the Desi Guide to Personal Finance
- Default Alive or Default Dead?
- The FIRE movement
- Prepping for the next Recession
- The Shockingly Simple Math Behind Early Retirement
- The 4% Rule: The Easy Answer to “How Much Do I Need for Retirement?”
- Save Like A Pessimist, Invest Like An Optimist
- How to Prosper in an Economic Boom - For 2013, maynot be applicable now
- Are You Cleaning Out Your Own Wallet?
- Getting out of the country, even within the same country: moving from Bengaluru to Varkala can be a huge income saver for most techies
- Let's Talk money -
-
- Mentorship sessions to help students in research
- Free NLP assignments - Useful when teaching
- Reflecting On My Failure To Craft Luck
- How to read and understand a scientific paper: a guide for non-scientists
- How-to-Read-Papers-for-ideas
- Making Money, Making Happiness
- Decomplication: How to Find Simple Solutions to “Hard” Problems
- Level 3 Thinking: A Unified Theory of Self - Improvement
- Real-time Machine Learning For Recommendations
- What Machine Learning Can Teach Us About Life: 7 Lessons
- Blog on writing everyday
- Offers 1:1 Career Advice calls
- You Don't Really Need Another MOOC
- Useful vs. Useless Feedback
- Masters/PhD application Advice by Andrew Trask -> Apply to work with a professor more than a dept/uni if possible ...
- Compilation of resources for applications
- Alexey Grigorev on His Career, Data Science, and Writing
- How Reading Papers Helps You Be a More Effective Data Scientist
- The Effects of Sequence and Delay on Crowd Work
- Chip Huyen: Four lessons I learned after my first full-time job after college
- Informal Mentors: Chip Huyen on Her Career, Writing, and ML
- NLP Trends and Use Cases in 2020
- Triple Thread : Career Advice
- Standing Out at Work
- Where to go and why
- Five Nonobvious Remote Work Techniques
- How to Accomplish More with Less - Useful Tools & Routines
- This Is The First 10 Years Of Your Career
- Don't End The Week With Nothing
- Act Like You're 35.What I wish I knew when I was 20 about Workplace
- Reach Out, Stay in Touch and Deepen Your Connections with This Essential Networking Advice
- What happens if your job is automated en masse?
- 5 Habits of Highly Effective Data Scientists
- Embrace Beginner's Mind; Avoid The Wrong Way To Be An Expert
- Book: How to Deal with Bullies at Work - 13%
- Data Science and Agile (What works, and what doesn't)
- Why efficiency is dangerous and slowing down makes life better
- Unpopular Opinion - Data Scientists Should Be More End-to-End
- Tweet: On what an ML Engineer is expected to do
- Research Statement from a FAIR candidate
- A compilation of research advice(s) for doing good research and writing good papers.
- Book: Riot
- Book: Stoicism -
78% - Book: A Gentleman in Moscow -
9% - Book: Why We Sleep? -
37% - Book: The Psychology of Money -
24% - Book: Into the Woods -
47% - Book: No Country for Old Men -
12% - Book: Meditation and its methods -
49%- Boring. Got the gist - Book: The Shadow Lines -
38% - Book: Absolute Power -
2%
- [Daily writing sessions - 4]
- [Session on CI/CD using CML in Gitlab]
- TaxiNLI dataset - NLI example in the MultiNLI dataset with 18 features like Linguistic, Logic, Knowledge etc
- Standardizing Indic NLP - Scripts for downloading various Indic NLP datasets and converting them into a standard format
- QED: A Framework and Dataset for Explanations in Question Answering
- Clinical NER datasets collection -> CADEC, ADE corpus, i2b2/n2c2 2018, MIMIC-3 & UK-CRIS
- Contract Understanding Atticus Dataset
- Twitter post mentioning major concepts in Limited-Data Setting
- Adaptive Name Entity Recognition under Highly Unbalanced Data